Automatische Bestimmung - Statistik
20.01.2019In der täglichen gutachterlichen Praxis ist die automatische Bestimmung von Arten an Hand der Ortungsrufe nicht mehr wegzudenken. Mit wenigen Ausnahmen steckt hinter diesen Programmen eine ausgeklügelte Statistik. Aber selbst die beste Statistik ist nicht fehlerfrei, jedoch ist es für den Anwender unmöglich zu erkennen, welche Fehler die verwendete Software denn macht oder hat.
Okay, im Folgenden mal ein kurzer Versuch zu erklären, wie und welche Fehler bei der automatischen Bestimmung auftreten - weniger aus Sicht unbekannter Rufe, sondern vielmehr auf Grund von Grenzen und Arbeitsweise der Statistik. Ich versuche das mal vereinfacht wiederzugeben und bitte mir zu entschuldigen, dass dabei manchmal Kleinigkeiten einfach so weggelassen oder eben simplifiziert werden.
Die statistische Artbestimmung anhand von Rufmesswerten basiert auf einem im Vorfeld durchgeführten Training - die Algorithmen erlernen quasi anhand bekannter Rufe das Spektrum der einzelnen Arten. Bei der Analyse von Aufnahmen durch den Anwender wird dann ermittelt, wie sich diese Aufnahmen in den Messwerteraum der Trainingsaufnahmen einfügen. Daraus ergeben sich Ähnlichkeiten zu bekannten Rufen. Die größte Ähnlichkeit bestimmt dann das Artergebnis. Sind die Rufe von anwesenden Arten generell sehr ähnlich, wird das System häufig Verwechslungsfehler machen. Diese sind in Abhängigkeit der Überlappung des Rufspektrums nur für manche Ruftypen, oder aber für beinahe alle Rufe zu erwarten. Entsprechend der Verteilung der Rufe sind Fehlerraten von 20% bis 50% möglich. Das folgende Bild zeigt dies beispielhaft für zwei Arten und eine Trennung anhand von zwei Rufmerkmalen.
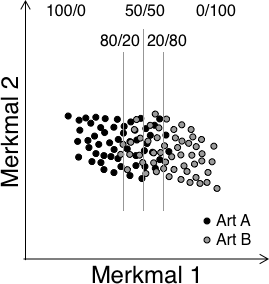
Bei ungünstiger Wahl der Trainingsrufe, ebenso wie an Standorten mit abweichenden Rufen, können große Unsicherheiten und damit Fehlbestimmungen entstehen (folgendes Bild). Sind die Rufe zum Beispiel einer Art im Habitat im vergleich zu den Trainingsrufen anders im Parameter-Raum verteilt, dann kann die Statistik häufig nur versagen. Dies führt zu fehlerhaften Bestimmungen, aber es erschwert auch die Beurteilung der Qualität der automatischen Bestimmungsergebnisse.
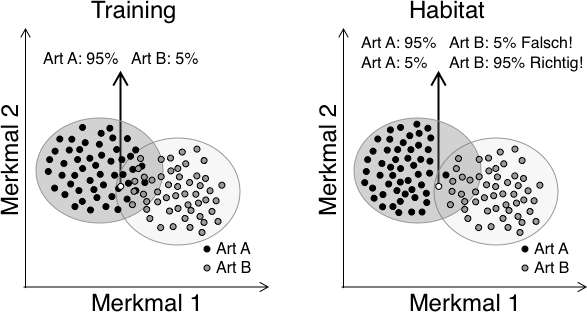
Weichen die eigenen Rufe von denen des Trainings stark ab, dann werden andere Fehler auftreten, als für das System prinzipiell gelten. Oder aber - die Fehler des Systems lassen sich eigentlich nicht pauschal angeben, da sie von den für tests verwendeten Rufen abhängen. So kann ein System im Test 90% korrekte Bestimmungen liefern, und im nächsten Test nur 30%. Generell ist somit die pauschale Wirksamkeit eines Bestimmungswerkzeugs nur schwer zu charakterisieren.
Was sagen nun also die vom Programm ermittelten Bestimmungswahrscheinlichkeiten aus? Eignen Sie sich festzulegen, welchen Bestimmungen man vertraut und welche man besser überprüft. Jein. Ein ganz klares Jein. Ganz vieles hängt natürlich damit zusammen, wie diese Sicherheit berechnet wird, und welches statistische System zu Grunde liegt. Auch 100% Sicherheit bei der Bestimmung kann bedeuten, dass die Bestimmung falsch ist. Aber der Reihe nach.
Es müssen prinzipiell zwei Fehler unterschieden werden, wenn man sich mit der Bestimmungssicherheit beschäftigt. Diese zwei Fehler sind falsch-positive ebenso wie falsch-negative Bestimmungs-Ergebnisse. Sie sind unabhängig von einander und gehen am besten aus sogenannten Verwechslungstabellen hervor. Damit kann auch Wirksamkeit sowie Sensitivität eines Verfahrens ermittelt werden. Die Wirksamkeit entspricht dem Anteil der richtig einer Art zugeordneten Rufe an den insgesamt der Art zugeordneten Rufen. Die Sensitivität zeigt den Anteil der richtig zugeordneten Rufe einer Art an der Gesamtheit ihrer Rufe. Üblicherweise werden diese beiden Charakteristika mit Testrufen ermittelt. Bei der Anwendung mit Habitatrufen kann vor allem die Wirksamkeit besonders stark schwanken: Fehlen Arten am Standort, können diese dennoch als Ergebnis der Bestimmung erscheinen - man denke nur an Rauhhaut- und Weißrandfledermaus. Die Bestimmung der nicht anwesenden Art ist dann zu 100% falsch.
Fazit
Eine einfache Beschreibung der Qualität einer Bestimmungssoftware ist nicht möglich, hängt diese doch sehr vom Testdatensatz ab. Bei jedem Anwender kann sich das - bedingt durch andere Aufnahmen - deutlich unterscheiden. Durch ein möglichst großes Spektrum an Rufen - und Abdeckung der Variabilität - wird die Qualität bei Tests ähnliche Ergebnisse liefern. Jedoch wird sich durch die Überlappung der Rufe von Arten dann vielleicht ein schlechteres Ergebnis ermitteln lassen, als bei einer unzureichenden Trainingssituation.
Solange es keine umfangreichen sicheren Testdatensätze gibt, wird sich ein repräsentativer Vergleich der Qualität von Systemen nicht durchführen lassen. Solch ein Testdatensatz sollte nicht nur sichere Aufnahmen jeder Art enthalten, sondern auch eine umfassende Variabilität. Nur so ergeben sich Rückschlüsse auf die Wirksamkeit und Sensitivität des Systems beim Einsatz mit Habitataufnahmen.
Welche Ergebnisse können wir generell erwarten? Meiner Meinung nach wären sichere 70% korrekte Bestimmungen bei Habitataufnahmen ein Traum. Bei der Verwendung nur guter Aufnahmen liesse sich das nochmals steigern. Und genau das ist eines der Probleme: die Aufnahmequalität. Denn wird diese schlechter, wird auch die Bestimmung schlechter. Wenn ich die Aufnahmen sehe, die mir zur Nachbestimmung gesendet werden, oder die im Internet für diesen zweck geposted werden, dann stimmt mich das manchmal traurig. Viele der Aufnahmen weisen Rufbruchstücke oder starke Echos auf. Da kann eine automatische ebensowenig wie eine sichere manuelle Bestimmung klappen. Wir brauchen wenige gute und eben nicht viele schlechte Aufnahmen.